
MySQLやPostgreSQLで使用しているB+木と、SpannerやTiDBで使用されているLSM木の違いについて、検索と挿入/削除の何が違うのかをコストの観点で解説をしていきます。
検索と挿入/削除はトレードオフの関係
B+木とLSM木などのデータ構造は、検索と挿入/削除の操作によって最適化をしている。それらの操作はお互いにコストが異なるため、トレードオフが発生します。検索を効率化しようとすると、挿入/削除にコストがかかってしまい、挿入/削除を効率化しようとすると検索のコストがかかってしまいます。
結論から言うと、B+木は読み取りは高速だが、書き込みが遅く、逆にLSM木は書き込みが高速だが、読み取りが遅くなります。
B+木とLSM木それぞれのデータ構造についての説明をしていきます。
B+木
B木について
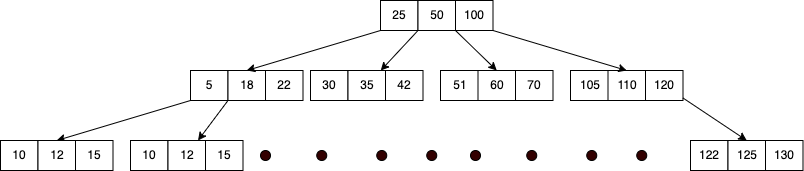
Bツリーは、バランスの保たれた2分木などの探索木を基礎として構築され、ファンアウト(ノードごとに許容されている子の最大数)が大きく、高さがが低いのが特徴です。
B+木とは
B木とB+木の主な違いは、B+木が全てのデータをリーフノードで持っているところで、中間ノードにはセパレータキー(ツリーをサブツリーに分割するためのキー)のみを格納している。そのため検索と挿入/削除などの操作は全てリーフノードにのみ影響がある。
検索
次数をb、データの総数をNとすると探索のコストはO(\(log_b N\))になります。bを2と考えると2分木と同じになり、探索にO(\(log_2 N\))になると想像がつきやすいかもしれないです。
挿入/削除
データーベースはインデックスの順序とツリーのバランスを保つ必要があり、どこのリーフノードに挿入するか探索する必要があり探索コストと同じO(\(log_b N\))だけコストが発生しする。また目当てのリーフノードが見つかったら保存できるだけの空き容量があるかを確認する。空きがない場合はリーフノードを分割して、エントリを新旧のノードの間に保存する。
LSM木
LSM木はイミュータブルなディスク上のストレージ構造で、挿入、更新および削除の操作において、ディスク上でデータレコードを探す必要がない。その結果として、書き込みの性能とスループットが大幅に改善する。その代わりに内容の重複が許容され、競合は読取時に解決している。
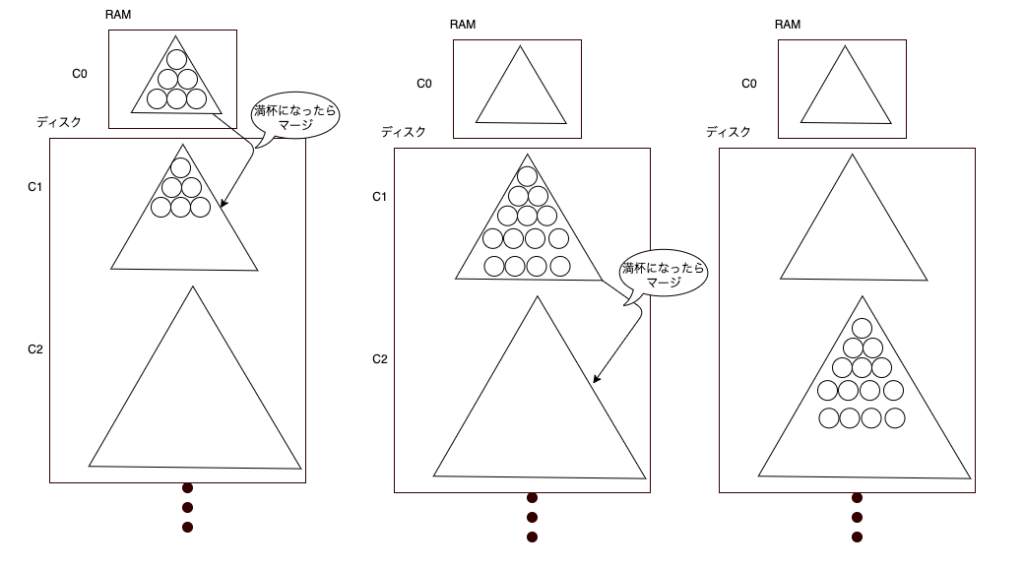
LSM木はk個のコンポーネントC0、C1、C2……Ckから構成されており、C1がC0よりN倍(2倍以上)大きいサイズ設定されて、C2はさらにC1よりN倍と、N倍ずつ大きいサイズになっている。
以下の図のように、各コンポーネントがある上限を超えると、そのレベルのコンポーネントが次のコンポーネントにマージされる。
C1が満杯で、C2にマージする時に、C2にはC1とC2のデータをマージソートした要素が持つことになる。
検索と挿入/削除
LSM木では、挿入や更新、削除の操作にデータの探索は必要ないため、処理が高速になる。
その代わりに読取時に冗長なレコードが発生してしまい、競合を読み込み時に解決するため読み込みが遅くなる。ブルームフィルターというある要素がテーブルに含まれている可能性があるか、テーブルに含まれていないかが確実であるかを判断するデータ構造があるが、範囲クエリーに関しては特定のデータを探すクエリーほど効果的ではない。
まとめ
B+木とLSM木で検索と挿入/削除の重視しているところが違うことについて解説をしてきました。
他にもGoについてや低レイヤーの記事を書いているので、そちらも読んでもらえたらと思います。
【おすすめ記事のリンク】


参考


コメント